Predicting dog breeds using Deep Neural Networks
This is a write up for the project neural-networks-dogbreed found here.
We have dreamed of artificial forms that are capable of making autonomous decisions and drastically increase our productivity. But up until recent history, visual object identification has been something that only intelligent life has been capable of doing, ... or at least in complex scenarios. The human interest for vision systems continue today and have lead to an incredible research. From autonomous driving to security applications, computer vision has become a key field of artificial intelligence.
Let's build a project to demonstrate some state-of-the-art techniques in computer vision. Yes, let's apply that to some common taks that we take for granted. Let's identify dog breeds.
Good news are that computers are able to tackle the challenge in a programmatic way. Breeds can be learned, and estimated in a more reliable way that with humans.
Transfer Learning and CNN
The backend demonstrates the concept of Transfer Learning by leveraging existing models and building on top of pre-trained convolutional neural networks (CNN). These models are used to identify dogs or humans, and later to predict the dog's breed. The project can be found here
This project is built on python, let's describe the main libraries used:
- TensorFlow: End-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources. https://www.tensorflow.org
- Keras: Deep learning API running on top of TensorFlow. It was developed with a focus on enabling fast experimentation. https://keras.io
- Dlib: Toolkit containing machine learning algorithms http://dlib.net
- Open-CV: Open Source Computer Vision Library. Includes several hundreds of computer vision algorithms and image processing functionality. https://opencv.org
- Numpy: Fundamental package for numerical computing with Python. https://numpy.org
- Flask: Lightweight framework for building web applications in python. https://flask.palletsprojects.com
- Waitress: production-quality pure-Python WSGI server with "very acceptable" performance. https://github.com/Pylons/waitress
Deep Learning
To answer the question what objects are where, a computational model needs to run through the data (image) and identify patterns or "features". The extracted features allow the model to hypothesize over the presence of an object. We might call each extraction step a transformation. These transformations might also exist in the form of image processing steps, such as color mapping or scaling.
To achieve complex object detection, these computational models attempt to create high-level abstractions using architectures that support multiple and iterative transformations. This particular approach is known as Deep Learning, characterized by a layered and often non-linear architecture. Each detection task will use a specific prediction model. For instance, the model detecting a human's face will be different from the model that infers dog breed.
Dog vs Human differentiation
We implement two different models in order to infer whether we are looking into a dog's or a human's face. Since our main subject is the former, we look for dogs first and fallback to human detection only if necessary. Dog-human identification will be mutually exclusive for sake of simplicity. That is, we will not be handling multiple simultaneous object detection for one image.
Data
Deep learning models are characterized by their need for very large datasets to be trained with. In addition, data (images in this case) must be expressed in matrix or tensor forms.
Detecting dogs
To fullfil the main case of our application, we need to start by ensuring that a dog exists in the image. We will leverage existing projects and deep learning models described in the next section. Since this is an image problem, it makes sense that we go por spatial convolution techniques.
Using ImageNet and the ResNet model
ImageNet [3] is an amazing project to provide researchers around the world with image data for training large-scale object detection models. The project compiles over 1.2 million images from the public domain. In a very expensive labeling effort, images are organized into 1000 categories that represent objects that we encounter in our day-to-day life. Such as vehicles, household objects, and animals.
However, when referring to ImageNet, we often refer to their annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC). A challenge that serve as a benchmark (and has motivated) some of most sophisticated object detection algorithms to date.
Out of the 1000 labels used in ImageNet, 133 correspond to breeds of dogs. This makes ImageNet scope ideal for our project.
Various models have been benchmarked against the ImageNet challenge. To mention some:
- VGG16 and VGG19 [4]
- ResNet [5]
- Inception V3 [6]
- Xception [7]
ResNet-50 stands for Residual Network and is a type of convolutional neural network (CNN). The model, presented in 2015, demonstrated extremely deep networks for its time (50 layers). The particularity of ResNet resides on its architecture, where the main architecture is composed by a collection of micro-architectures. Due to its popularity, ResNet models are now conveniently included in the Keras python library.
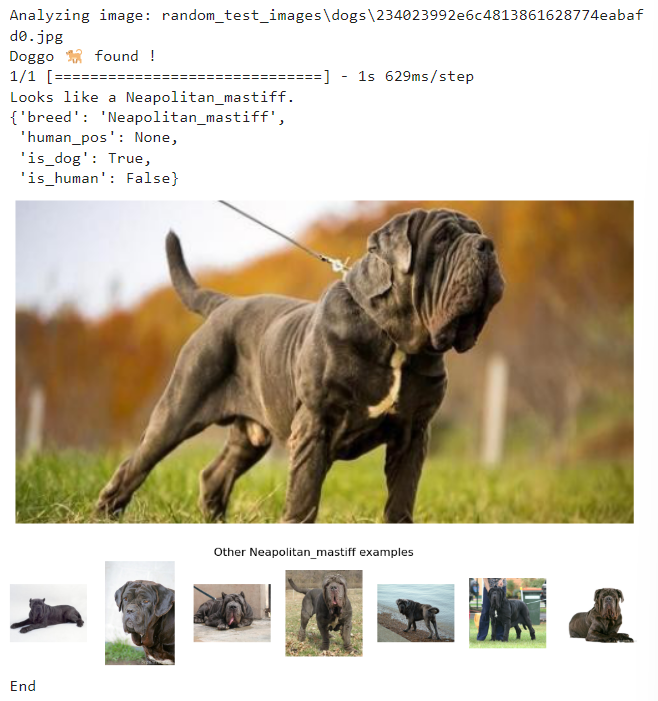
Detecting dogs with ResNet-50
We implement ResNet-50 to answer our first question Is there a dog in the picture ?. By running the complete base model (original layers as specified in the 2015's paper) and by passing the ImageNet weights, we let the model predict the existence of dogs in our images.
A check on a test set of 100 images yielded the following results:
- On a 100 image dataset containing only humans, the model predicted 0 humans.
- On a 100 image dataset containing dogs, the model predicted 100% dogs.
These demonstrate the accuracy of this model (see notebook for more details).
Detecting humans (two different approaches)
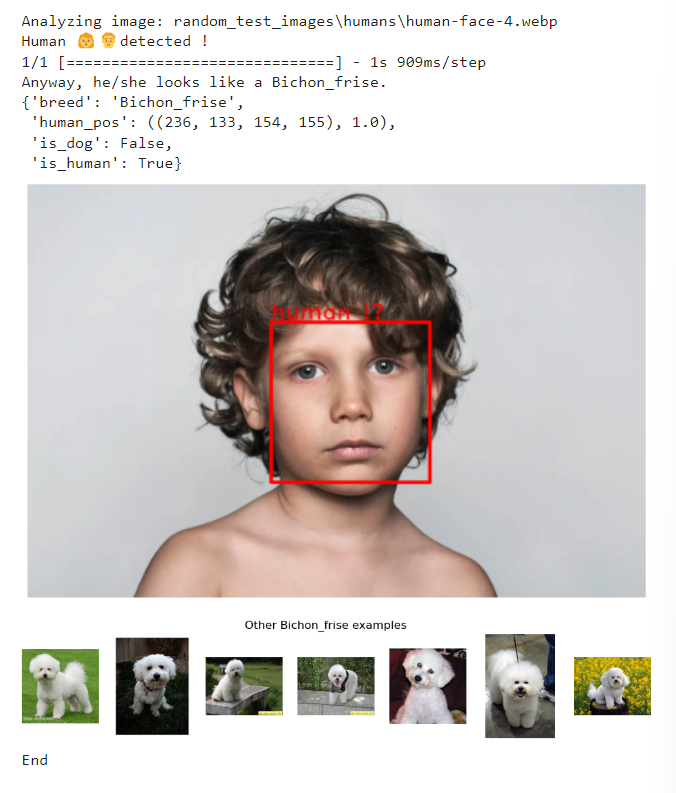
If a dog is not detected, our main algorithm will attempt to find a human face. We explored two different methods for human face detection included in Dlib's python library [8] : Histogram of Oriented Gradients (HOG) and the more powerful convolutional neural detector (MMOD-CNN) [9].
By running the same check on our test set, we obtain the following results:
- On a 100 image dataset containing only humans
- HOG detected 99%
- MMOD-CNN detected 100%
- On a 100 image dataset containing dogs, the model predicted 100% dogs.
- HOG detected 8%
- MMOD-CNN detected 2%
Histogram of Oriented Gradients (HOG) appears to have very efficient computation time. Furthermore, it seems to be more accurate than Haar-like models when finding human faces (99% vs 97%). Again, the results where very close, but slightly better in the dog dataset. Convolutional Neural Network MMOD had a 100% detection rate for human pictures. However, the computational times are very high and might not suitable for our application.
Due to the lower priority for human detection in our project context, we accept the error level of the Histogram of Oriented Gradients and choose it for its fast implementation.
Predicting breed with Xception
To perform our main prediction task we will build upon another popular convolutional neural network known for its higher accuracy results on the ImageNet dataset. The Xception model [7]. By using Xception as a base model, we can leverage it's pre-trained features on our particular breed detection problem.
To predict only dog's breed, the model has to be adjusted to work only with dog breeds. In a demonstration of transfer learning, we make use of Xception's pre-trained model by importing only the base layers and then construct final layers on top of it. In other words, the final layers will be tailored to our particular needs, while taking full advantage of the pre-trained model.
Since we already have a pre-processed set of Dog bottleneck features for Xception, we add two top layers : A global spatial average pooling layer and a fully connected layer designed to distinguish between the 133 breeds. After some trials, we concluded that the model's accuracy does not improve substantially after 10 epochs. When testing against our validation set, we attain an accuracy of 85%.
Conclusions
We have explored artificial vision technologies in the context of a real-world problem. As the technology becomes widely available to the common user, we acknowledge the huge advancement done in the field in the recent years.
Three major identification techniques where explored for human face recognition: Histogram of Gradients and Haar-Like features and Convolutional Neural Networks. It became evident that convolutional neural networks are much more accurate than the former two techniques, but takes much more computational power to run. When it comes to choosing the right predictor, finding the right compromise between accuracy and speed is very much dependant by the final use-case.
Two state-of-the-art convolutional neural network architectures where explored for our dog related predictions. Both ResNet-50 and Xception (weighted for the ImageNet dataset) proved to be the right choice for our project, largely due to the fact that pre-trained models are easily available. By applying transfer learning, we where able to adapt Xception to our particular problem, achieving a final accuracy of 85.4%. After a final visual inspection, it is very clear that this is no simple task even for the human eye! and that an accuracy of this level might as well be a very acceptable outcome.
References
[1] Udacity project repository. Udacity.com. 2022.
[2] The earliest applications were pattern recognition systems for character recognition in office automation related tasks : L. G. Roberts, Pattern Recognition With An Adaptive Network, in: Proc. IRE International Convention Record, 66–70, 1960 and J. T. Tippett, D. A. Borkowitz, L. C. Clapp, C. J. Koester, A. J. Vanderburgh (Eds.), Optical and Electro-Optical Information Processing, MIT Press, 1965.
[3] ImageNet Large Scale Visual Recognition Challenge. Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. IJCV, 2015.
[4] Very Deep Convolutional Networks for Large Scale Image Recognition.Simonyan and Zisserman. 2014.
[5] Deep Residual Learning for Image Recognition. He et al. 2015.